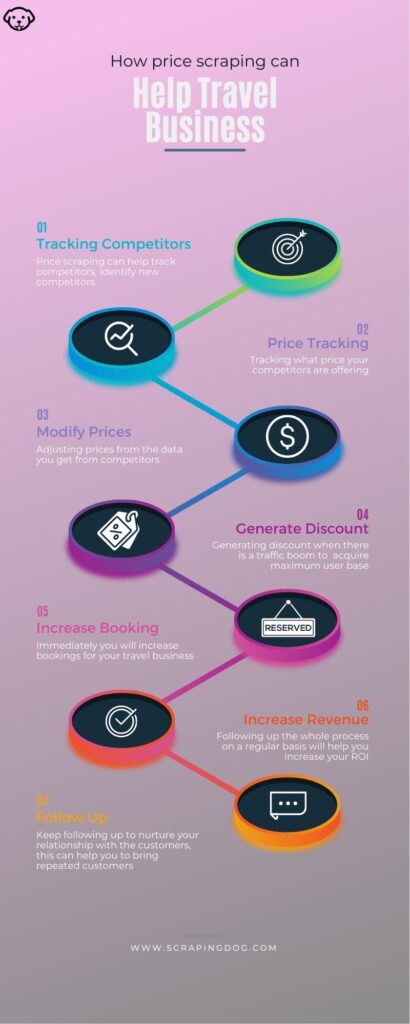
Information Scraping Vs Data Crawling: The Distinctions Lots of people alike speech refer to the two as if they coincide procedure. While at face value they may appear to offer the exact same outcomes, the methods made use of are really various. Both are important to getting data however the process included and the type of information demanded differ in various methods. Typically, in internet data extraction jobs, you need to combine creeping and scraping. So you first creep - or uncover - the URLs, download the HTML documents, and afterwards scuff the data from those documents. Not only do they check out web pages, but they additionally collect all the pertinent info that indexes them in the process. They additionally look for all links to the relevant web pages in the process. Data scuffing is necessary for a firm, whether it is for the purchase of consumers, or service and profits growth. Data scuffing services are capable of performing actions that can not be carried out by software crawling devices. Things like javascript execution, submission of data formats, defying robots guidelines-- all are a point information scraping solutions can manage. Regardless of all the distinctions, web scraping and internet crawling have particular shortcomings.
- Information scraping involves drawing out specific information from a website, typically utilizing automated tools.Information crawling describes the process of gathering information from non-web sources, such as inner databases, tradition systems, and other information repositories.Our team of dedicated and committed professionals is an unique mix of technique, creativity, and modern technology.
Expert Solutions Are Required
Scrapes do not have to bother with being polite or following any honest regulations. Crawlers, however, have to make sure that they are polite to the servers. They need to operate in a manner such that they don't offend the web servers, and need to be dexterous enough to extract all the information required. Most of the time, this info obtains duplicated, and several web pages end up having the very same data. While the robots don't have any type of means of identifying this replicate info, doing away with the same information is necessary. Therefore, data de-duplication ends up being a component of internet crawling.What Is Data-as-a-Service (DaaS)? - Built In
What Is Data-as-a-Service (DaaS)?.
Posted: Fri, 23 Jun 2023 19:00:52 GMT [source]